面试问题
深度学习基础网络
-
LeNet的结构
它的输入图像为32×32的灰度值图像, 后面有3个卷积层, 1个全连接层和1个高斯连接层(该层用来计算Loss, 现代版本已用softmax Loss取代).
- [input/32×32×1]
- [C1 conv/5×5/s1/28 28×28×6] - [S2 avg pool/2×2/s2 14×14×6] - [sigmoid]
- [C3 conv/5×5/s1/16 10×10×16] - [S4 avg pool/2×2/s2 5×5×16]
- [C5 conv]
- [FC6]
- [output]
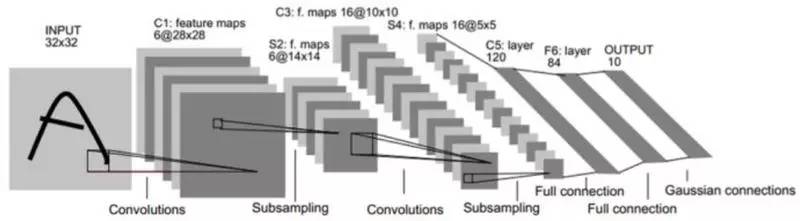
LeNet5最初的特性有如下几点:
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样(Subsample)的平均池化层(Average Pooling)
- 双曲正切(Tanh)或S型(Sigmoid)的激活函数
- MLP(全连接层)作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂度
-
AlexNet的结构
AlexNet包含了6亿3000万个连接, 6000万个参数和65万个神经元, 拥有5个卷积层, 其中3个卷积层后面连接了最大池化层, 最后还有3个全连接层.
- [input]
- [conv/11×11/s4/96 - ReLU - lRN - Max-pool/3×3/s2]
- [conv/5×5/s1/256 - ReLU - lRN - Max-pool/3×3/s2]
- [conv/3×3/s1/384 - ReLU] * 2
- [conv/3×3/s1/256- ReLU - Max-pool/3×3/s2]
- [fc 4096 - ReLU] - [fc 4096 - ReLU]
- [fc 1000]

我们可以发现一个比较有意思的现象, 在前几个卷积层, 虽然计算量很大, 但参数量很小, 都在1M左右甚至更小, 只占AlexNet总参数量的很小一部分. 这就是卷积层有用的地方, 可以通过较小的参数量提取有效的特征.
虽然每一个卷积层占整个网络的参数量的1%都不到, 但是如果去掉任何一个卷积层, 都会使网络的分类性能大幅地下降.
AlexNet将LeNet的思想发扬光大, 把CNN的基本原理应用到了很深很宽的网络中. AlexNet主要使用到的新技术点如下:
- 成功使用ReLU作为CNN的激活函数, 并验证其效果在较深的网络超过了Sigmoid, 成功解决了Sigmoid在网络较深时的梯度弥散问题. 虽然ReLU激活函数在很久之前就被提出了, 但是直到AlexNet的出现才将其发扬光大.
- 训练时使用Dropout随机忽略一部分神经元, 以避免模型过拟合. Dropout虽有单独的论文论述, 但是AlexNet将其实用化, 通过实践证实了它的效果. 在AlexNet中主要是最后几个全连接层使用了Dropout.
- 使用重叠的最大池化. 此前CNN中普遍使用平均池化, AlexNet全部使用最大池化, 避免平均池化的模糊化效果. 并且AlexNet中提出让步长比池化核的尺寸小, 这样池化层的输出之间会有重叠和覆盖, 提升了特征的丰富性.
- 提出了LRN(local Response normalization)层, 对局部神经元的活动创建竞争机制, 使得其中响应比较大的值变得相对更大, 并抑制其他反馈较小的神经元, 增强了模型的泛化能力.
- 使用CUDA加速深度卷积网络的训练, 利用GPU强大的并行计算能力, 处理神经网络训练时大量的矩阵运算. AlexNet使用了两块GTX580 GPU进行训练, 单个GTX580只有3GB显存, 这限制了可训练的网络的最大规模. 因此作者将AlexNet分布在两个GPU上, 在每个GPU的显存中储存一半的神经元的参数.
- 数据增强, 随机地从256256的原始图像中截取224224大小的区域(以及水平翻转的镜像), 相当于增加了(256-224)*22=2048倍的数据量. 如果没有数据增强, 仅靠原始的数据量, 参数众多的CNN会陷入过拟合中, 使用了数据增强后可以大大减轻过拟合, 提升泛化能力. 进行预测时, 则是取图片的四个角加中间共5个位置, 并进行左右翻转, 一共获得10张图片, 对他们进行预测并对10次结果求均值.
-
VGGNet的结构
VGGNet探索了卷积神经网络的深度与其性能之间的关系, 通过反复堆叠33的小型卷积核和22的最大池化层, VGGNet成功地构筑了11~19层深的卷积神经网络.
VGGNet中全部使用了33的卷积核和22的池化核, 通过不断加深网络结构来提升性能. VGGNet拥有5段卷积, 每一段内有2~3个卷积层, 同时每段尾部会连接一个最大池化层用来缩小图片尺寸.
注意: 3个33的卷积层串联的效果则相当于1个77的卷积层. 除此之外, 3个串联的3*3的卷积层的作用有:
-
参数数量减少了45%(1 - 27/49): 3个串联的33的卷积层的参数数量为333Input_size, 1个77的卷积层的参数量为77*Input_size.
-
具有更多的非线性变换, 使得CNN对特征的学习能力更强. 3个33的卷积层可以使用三次ReLU激活函数, 1个77的卷积层只使用一次ReLU.
作者在对比各级网络时总结出了以下几个观点.
- LRN层作用不大.
- 越深的网络效果越好.
- 11的卷积也是很有效的, 但是没有33的卷积好, 大一些的卷积核可以学习更大的空间特征.
-
-
InceptionNet V1的结构
InceptionNet是由Inception module with dimension reductions堆叠形成的.
Inception module with dimension reductions如下图所示.
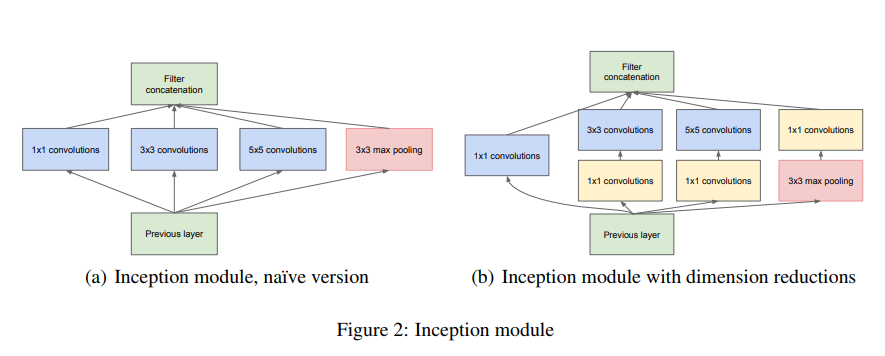
Inception module with dimension reductions的基本结构, 其中有4个分支:
第一个分支对输入进行11的卷积, 这其实也是NIN中提出的一个重要结构. 11的卷积是一个非常优秀的结构, 它可以跨通道组织信息, 提高网络的表达能力, 同时可以对输出通道升维和降维.
可以看到Inception Module的4个分支都用到了11卷积, 来进行低成本(计算量比33小很多)的跨通道的特征变换.
第二个分支先使用了11卷积, 然后连接33卷积, 相当于进行了两次特征变换.
第三个分支类似, 先是11的卷积, 然后连接55卷积.
最后一个分支则是33最大池化后直接使用11卷积.
假如输入是HW192, 下面对比一下Inception module的两个版本naive version, dimension reductions verison的参数量.
- 第一个分支: conv 1×1 64f, 是一样的, 参数量为1×1×192×64.
- 第二个分支: conv 3×3 128f, 参数量为 3×3×192×128; [conv 1×1 96f - conv 3×3 128f], 参数量为 1×1×192×96 + 3×3×96×128. 参数量减少了41.6%.
- 第三个分支: conv 5×5 32f, 参数量为 5519232; [conv 1×1 16f - conv 5×5 32f], 参数量为 1119216 + 5516*32. 参数量减少了89.6%.
- 第四个分支: max-pooling, 没有参数; [max-pooling - conv 1×1 32f], 参数量为 1×1×192×32. 参数量增加了100%
总的来说, 通过1×1 conv, 大大地减少了参数量, 这样使得网络可以更深、更宽.
Inception module with dimension reductions的4个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合).
GoogLeNet是InceptionNet v1的一个例子.
GoogLeNet含22层, 它的参数量是6.7977 million, AlexNet的参数量是60 million.
GoogLeNet的主要特点是:
- 使用了Inception module with dimension reductions, 其中含有很多的1*1卷积核, 极大地减少了参数量
- 用average pooling layer取代了fully-connected layer(紧跟最后一个卷积层), 减少了参数量
-
ResNet的结构? 其残差是怎么实现的?
-
ResNet最初的灵感来源——Degradation 在不断加神经网络的深度时, 会出现一个Degradation的问题, 即准确率会先上升然后达到饱和, 再持续增加深度则会导致准确率下降.
-
ResNet提出了一种残差模块, 如下图所示
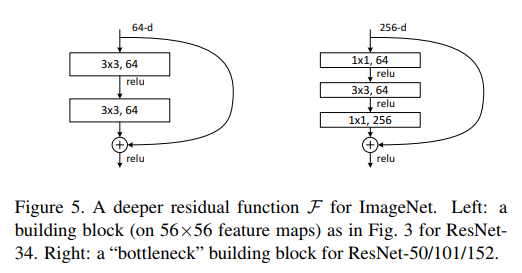
-
假定某段神经网络的输入是x, 期望输出是H(x), 如果我们直接把输入x传到输出作为初始结果, 那么此时我们需要学习的目标就是F(x)=H(x)-x. ResNet相当于将学习目标改变了, 不再是学习一个完整的输出H(x), 只是输出和输入的差别H(x)-x, 即残差
传统的卷积层或全连接层在信息传递时, 或多或少会存在信息丢失、损耗等问题. ResNet在某种程度上解决了这个问题, 通过直接将输入信息绕道传到输出, 保护信息的完整性, 整个网络则只需要学习输入, 输出差别的那一部分, 简化学习目标和难度.
-
-
以上个网络的比较图
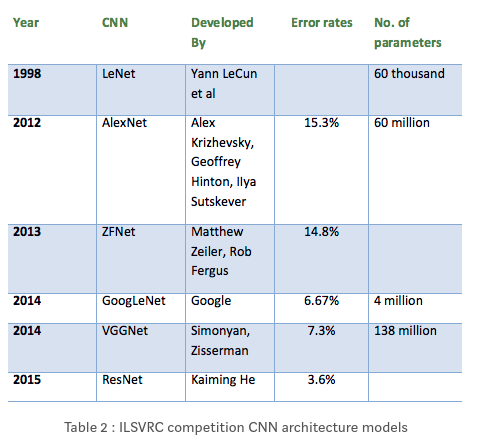
注: GoogLeNet的参数量是6.7977 million
目标检测模型
-
ROIPooling是怎么实现的(写出伪码)? 它的作用是什么?
ROIPooling的作用是生成固定大小的feature, 以适应后面的全连接层. 这样可以使得输入可以是任意大小的.
ROIPooling是一种池化核大小不固定, 输出大小固定的最大池化.
# ROIPooling的输入是conv_feature , of shape (H_in, W_in, C_in), ROIs, each roi is (x1, y1, x2, y2, index) # ROIPooling输出大小为pooled_feature, of shape (H_out, W_out, C_out), 其中C_out = C_in # image经过ConvNet后, 缩小的倍数为feat_stride conv_feature = ConvNet(image) (H_in, W_in, C_in) = conv_feature.shape RoIs = RegionProposalMethod(image) pooled_feature = np.zeros((H_out, W_out, C_in)) for RoI in RoIs: roi_h = (roi[3] - roi[1]) / feat_stride roi_w = (roi[2] - roi[0]) / feat_stride pool_window_h = roi_h / H_out pool_window_w = roi_w / W_out index = RoI[4] for i in range(H_out): start_h = roi[1] + i * pool_window_h end_h = start_h + pool_window_h for j in range(W_out): start_w = roi[0] + j * pool_window_w end_w = start_w + pool_window_w for c in range(C_in): pooled_feature[index, i, j, c] = max(conv_feature[start_h: end_h, start_w: end_w, c]) -
NMS是怎么实现的(写出伪码)? 它的作用是什么?
NMS对生成的bboxes按照它们的得分及其重合度进行过滤.
def nms(dets, thresh): x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] scores = dets[:, 4] areas = (y1 - x1 + 1) * (y2 - x2 + 1) order = np.argsort(-scores) keep = [] while order.size() > 0: i = order[0] keep.append(i) if order.size() == 1: break ix1 = np.maximum(x1[i], x1[order[1:]]) iy1 = np.maximum(y1[i], y1[order[1:]]) ix2 = np.minimum(x2[i], x2[order[1:]]) iy2 = np.minimum(y2[i], y2[order[1:]]) inter_area = np.maximum(ix2 - ix1 + 1, 0) * np.maximum(iy2 - iy1 + 1, 0) overlaps = inter_area / (areas[i] + areas[order[1:]] - inter_area) left_order = np.where(overlaps <= thresh)[0] + 1 order = order[left_order] return keep -
Region proposal network的构成? 作用?
RPN的作用:
- 预测anchor box的bbox偏移量, anchor box含目标物的概率
- anchor box作为reference, 表示不同的scale与ratio
- 无缝接入Fast R-CNN, 共用特征提取网络
- 实现一体化训练
- RPN产生proposal, 意思是它输出了anchor box的bbox偏移量, anchor box含目标物的概率, 根据偏移量与其参考anchor box, 可以计算得到proposal的坐标, 并带有含目标物的概率
RPN的特点:
- 它是一种全卷积网络, 输入是任意大小的feature map或image, 输出anchor box的bbox偏移量与anchor box含目标物的概率
- 它含一个卷积核大小为
3×3, 数量为256的中间卷积层, 后面接并列的两个卷积核为1×1的卷积层 - 一个
1×1卷积层负责预测anchor box的bbox偏移量, 卷积核数量为4×scale的个数×ratio的个数 - 另一个
1×1卷积层负责预测anchor box的含与不含目标物的概率, 卷积核数量为2×scale的个数×ratio的个数, 后面还带有reshape操作, softmax操作, reshape操作
RPN(test time)的结构如下图所示.

-
Faster R-CNN与SSD的区别
- 首先, Faster R-CNN是两阶段的, 先提出proposal, 再对proposal进行分类与回归 而SSD是一阶段的, 它把目标检测问题转换为回归问题, YOLO也是这样.
CNN的基础元素
-
卷积层的前馈传播, 反馈传播是怎么实现的?(代码)
-
最大池化的前馈传播, 反馈传播是怎么实现的?(代码)
-
平均池化的前馈传播, 反馈传播是怎么实现的?(代码)
-
batch normalization的前馈传播, 反馈传播是怎么实现的?(代码)
-
激活函数ReLU, sigmoid, tanh, Leaky ReLU
-
全连接层的前馈传播, 反馈传播是怎么实现的?
-
Dropout的前馈传播, 反馈传播是怎么实现的?(代码)
-
softmax函数的公式? 它的作用?
-
目标函数–Loss函数
-
分类loss
-
回归loss
-
