论文题目: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文作者: Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
提交时间: 2015-06-04(v1), 2016-01-06(v3, last)
Faster R-CNN (test time)
Faster R-CNN(test time)由4个部分组成:
-
特征提取网络ConvNet. 输入是Image, 输出是Conv feature map
-
Region Proposal Network. 输入是Conv feature map, 输出是rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), 即a set of rectangular object proposals, each with an objectness score, 其中$k$是生成anchors时ratio个数与scale个数的乘积.
-
Proposal layer(python layer). 输入是rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), 输出是proposals
-
分类与定位, 包含ROIPooling, fc, softmax layer. 输入是conv feature map, proposals, 输出是 class scores(1×K), bbox predictions(1×4K)
Faster R-CNN (test time) 的流程图如下:
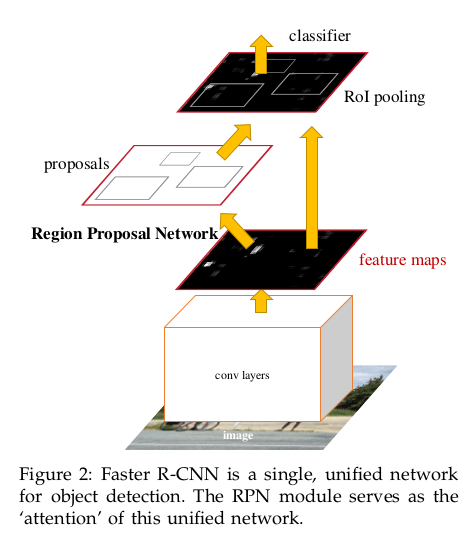
注意到, Fast R-CNN (test time) 的流程图如下:
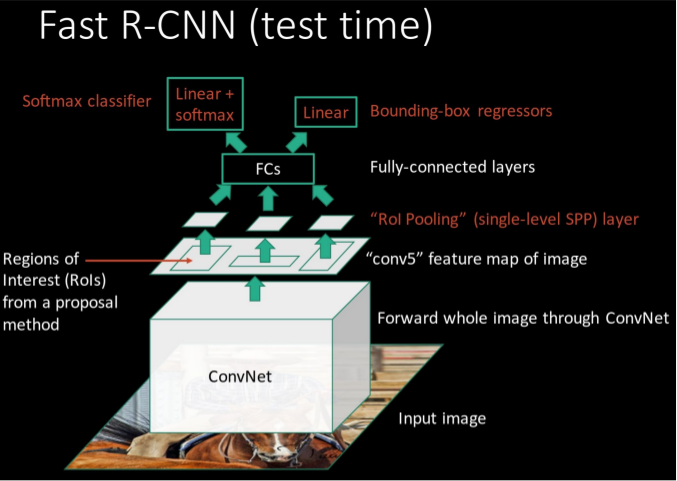
对比后可见, 相比于 Fast R-CNN (test time), Faster R-CNN (test time) 用 RPN 取代了 额外的 Proposal generating method, 将 RPN 直接接入了网络之中, 实现了一体化检测.
特征提取网络ConvNets
ConvNet 的基础网络, 作者选用了三种网络(论文里用了两种, 源码里用了三种):
- the Zeiler and Fergus model: 简称 ZF, 使用了
5个卷积层[input-data] - [conv/relu - norm - pool] * 2 - [conv/relu] * 3
- the Simonyan and Zisserman model: 简称 VGG-16, 使用了
13个卷积层[input-data] - [conv/relu - conv/relu - pool] * 2 - [conv/relu - conv/relu - conv/relu - pool] * 2 - [conv/relu - conv/relu - conv/relu]
- VGG-CNN-M-1024: 使用了
5层卷积层[input-data] - [conv/relu - norm - pool] * 2 - [conv/relu] * 3
Region Proposal Network
Region Proposal Network, 下面简称为RPN, 这是较Fast R-CNN增加的部分, 其取代了Selective search方法
RPN的任务——用来做什么的?
用来生成region proposals, 取代selective search等生成proposal的方法
region proposal network与selective search的不同之处
在Faster R-CNN, RPN的输入是conv feature map, 共用卷积层, 实现了联合训练.
而在Fast R-CNN中, Selective research的输入是整张图片, 图片通过CNN生成feature map, 还要通过Selective research生成Proposals. 显然, 这无法实现一体化, 并且比Selective Research耗时多.
RPN的结构及运行流
RPN是一种fully convolutional network, 即所谓的全卷积网络, 它的构成分test time, train time进行陈述.
输入是conv feature map of any size(也可以是a image of any size, 在Faster R-CNN中是conv feature map)
输入可以是
any size, 这是因为后面的ROIPooling, 它会得到fixed size的feature map.
输出是rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), 即a set of rectangular object proposals, each with an objectness score
需要注意的是, rpn_bbox_pred(1×4k×H×W)是相对于anchor box的bbox_targets(x,y,w,h),
每一种ratio-scale对应一种bbox_targets, 每一个location有$k$种ratio-scale型的anchor box, 则每一个location有$k$种bbox_targets(x,y,w,h)
RPN的网络流如下图所示, 其中$k$是生成anchors时ratio个数与scale个数的乘积.

anchor box —— serve as references
anchor box用来生成proposal: 由于RPN输出rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), 注意到rpn_bbox_pred(1×4k×H×W)是预测偏差量predicted bbox deltas, 进而anchor boxes + bbox targets, 这样就得到了未经筛选的proposals
anchor box可以理解为proposals半成品, serve as references at multiple scales and aspect ratios, 后续再通过处理得到proposals.
anchor box担当了reference的角色
在每一个location, 都会生成$k$个anchor boxes, 其中$k$是生成anchors时ratio个数与scale个数的乘积.
下面是针对RPN的输入为conv feature map的anchor boxes生成过程.
-
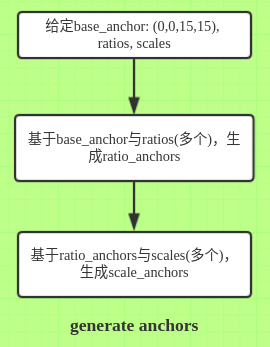
生成具有相对位置的anchor boxes:给定base_anchor的坐标(论文里是
3*3大小的base_anchor, 源码里是15*15), ratios, scales, 记$k$为ratios的元素个数与scales的元素个数的乘积, 生成个anchor boxes.先生成相对位置的anchor boxes是很棒的做法, 如此上述anchor boxes可以重复使用, 加上图片上的每一个location就可以快速地得到所有的anchor boxes.
-
生成整张图片的anchor boxes:给定feat_stride(原始图片到conv feature map的缩小比例), 将conv feature map的每一个location乘以倍数feat_stride, 再加上上述个anchor boxes, 如此便生成了整张图片的anchor boxes.
Proposal layer
基于RPN输出的rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), 生成proposals:
-
生成整张图片的anchor boxes: 按照上面提到的anchor box生成过程, 生成整张图片的anchor boxes.
-
得到未经筛选的proposals(proposal, prob):
RPN的输出rpn_bbox_pred(1×4k×H×W) + 整张图片的anchor boxes, 如此便得到未经筛选的proposals, 同时proposals还带有probs(即rpn_cls_prob_reshape(1×2k×H×W)), 因此这里得到了带有prob的proposal: (proposal, prob) -
去掉超高或超宽的proposals:
removepredicted boxes with either height or width < threshold -
排序:
sortall (proposal, prob) pairs by prob from highest to lowest -
take
top pre_nms_topNproposals before NMS -
apply
NMSwith threshold 0.7 to remaining proposals -
take
top after_nms_topNproposals after NMS -
return the remaining proposals (-> RoIs top, probs top)
Faster R-CNN(train time)
这里只讲RPN, 至于最后的classification与bbox_regress, 它们与Fast R-CNN是一样的
RPN的训练
在train time, 比test time多了一个部分, 即$Loss$部分.
输入(与test time一样): conv feature map of any size
输出是rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W), rpn_loss_cls, rpn_loss_bbox
定义正负样本及忽略型样本
RPN中的正样本anchor box表示, 该anchor box含object. 负样本anchor box, 表示该anchor box不含object.
论文原文是这样:
assign a positive label to two kinds of anchors: (i) the anchor/anchors with the highest Intersection-over- Union (IoU) overlap with a ground-truth box, or (ii) an anchor that has an IoU overlap higher than 0.7 with any ground-truth box
Note that a single ground-truth box may assign positive labels to multiple anchors. Usually the second condition is sufficient to determine the positive samples; but we still adopt the first condition for the reason that in some rare cases the second condition may find no positive sample.
assign a negative label to a non-positive anchor if its IoU ratio is lower than 0.3 for all ground-truth boxes.
Anchors that are neither positive nor negative do not contribute to the training objective.
在Faster R-CNN工程中, 实际如下:
- anchor box正样本: 与某个gt box具有最大IoU overlap的anchor box,
或者与所有gt boxes的IoU overlapes最大值大于0.7的anchor box, 正样本的
lable = 1(源码链接)这里的第二种正样本与论文里的有所区别, 论文里是与任何gt boxes的IoU overlap都大于0.7的anchor boxes
-
anchor box负样本: 与所有gt boxes的IoU overlapes都小于阈值的anchor boxes,
label = 0 - 忽略型样本: 非正非负,
label = -1
采样规则
由于在数据输入层, 每个mini-batch为一图片, 在RPN训练时, 每个mini-batch, 从该图片的anchor boxes中随机抽取256个anchor box,
其中正样本数量:负样本数量=1:1.
当正样本数量不够时,用负样本进行补充.
$Loss$函数
训练时, 每个mini-batch中的anchor box samples, 都有其anchor box label的真实值=1或0
下面需为其样本中每个anchor box, 指定与该anchor box具有最大IoU overlap的gt box为其对应gt box,
进而得到真实的bbox_targets, 记为anchor box的bbox_targets真实值
同时, RPN也为每个anchor box预测了probs to be and be not a object与bbox_targets,
可从rpn_bbox_pred(1×4k×H×W), rpn_cls_prob_reshape(1×2k×H×W)中获取.
如此, 每个anchor box都有了关于分类(anchor box是否含object)与定位(关于anchor box与其对应gt box的bbox_targets) 的真实值与预测值, 即
-
anchor box label的真实值: 记为 , 表示该anchor box
i为正样本(含object),
表示该anchor boxi为负样本(不含object) -
anchor box含object的概率: 记为 , 表示anchor box
i含object的预测概率, 这可从RPN输出之一rpn_cls_prob_reshape中获得 -
anchor box的bbox_targets真实值: 记为, 表示anchor box
i与其对应gt box的bbox_targets真实值, 计算公式如下: -
anchor box的bbox_targets预测值: 记为, 表示anchor box
i与其对应gt box的bbox_targets预测值, 这可从RPN输出之一rpn_bbox_pred中获取
有了分类与定位的真实值与预测值, 便可定义RPN的函数,
[未完待续]
