论文题目: Fast R-CNN
论文作者: Ross Girshick
1. 文章梗概
-
基于R-CNN与SPPnet, 提出了一个clean and fast update——Fast R-CNN
-
Fast R-CNN: 训练、测试时间、mAP较R-CNN有很大的提升(9×, 213× faster, 更高), 较SPPnet也有提升(3×, 10× faster, 更高), 均基于PASCAL VOC2012与VGG16 network
-
Fast R-CNN:
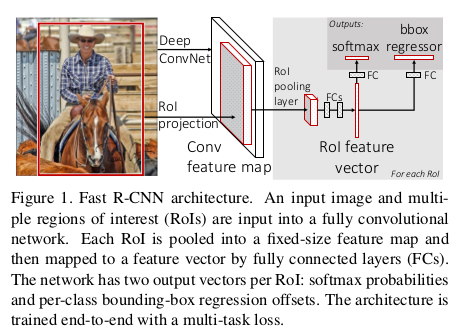
要点1: 一张图片一次性通过CNN提取特征, 再进行selective search与detection
要点2: 去掉warp过程, 增加ROI pooling layer, 目的是为了固定大小, 配合后面的全连接层
要点3: 把SVM检测器换成softmax检测器
要点4: 建立多任务loss函数(对于每个labeled RoI), 联合训练分类与bounding-box回归
要点5: 除selective search之外, 其他都整合为一个过程
要点6: 不需要disk storage(供特征提取使用)
Fast R-CNN 结构图如下(来源于论文Fast R-CNN):
2. 研究背景
-
现有的目标检测模型都是多阶段训练的, 这些模型是slow and inelegant
-
相比图像分类, 目标检测需要精确的定位, 而这会导致两个问题. 一是要处理的候选proposals非常多. 二是这些候选proposal只能提供粗放的定位. 因此, 对这些问题的解决方案要综合考虑速度、精度、简单度.
2.1. R-CNN的缺点
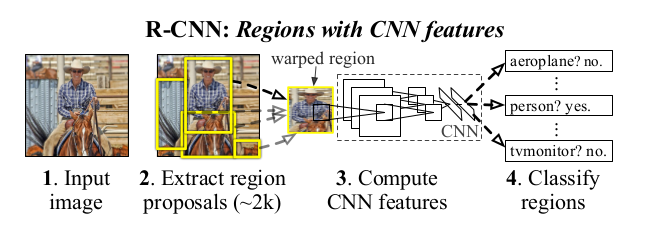
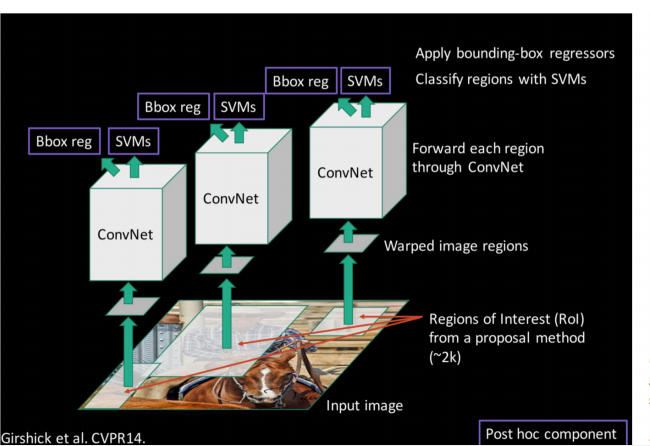
R-CNN目标检测系统的示意图如下, 下图1来自R-CNN论文, 图2来自Girshick et al. CVPR14
2.1.1. 多阶段训练
- fine-tuning: 首先利用log loss微调ConvNet(输入是region proposals), 输出ConvNet features
- 训练SVMs: 输入是ConvNet features, 这些SVMs取代上述fine-tuning阶段的softmax分类器
- 训练bounding-box回归器(输入是ConvNet pool5 features)
2.1.2. 训练在空间与时间上消耗大
-
SVM与bounding-box regression训练阶段所需的features从每张图片中的每一个region proposal中提取, 这些特征需要存储在硬盘中, 以供训练SVM与bounding-box regressor
-
训练耗时多, 存储特征需要很大的空间, 比如采用VGG16网络与VOC2007 trainval set, 训练用时为2.5天, 需要几百GB的存储空间用于存储特征.
2.1.3. 检测慢
- 采用VGG16网络, 在一块Nvidia K40 GPU(overclocked to 875 MHz)上, 测试时间为47s / image
- 慢的原因是每一个region proposal都要经过一次ConvNet, 每张图片在选择性搜索阶段产生 ~2000个region proposal, 也就是每张图片就要进行约2000次关于卷积神经网络的计算.
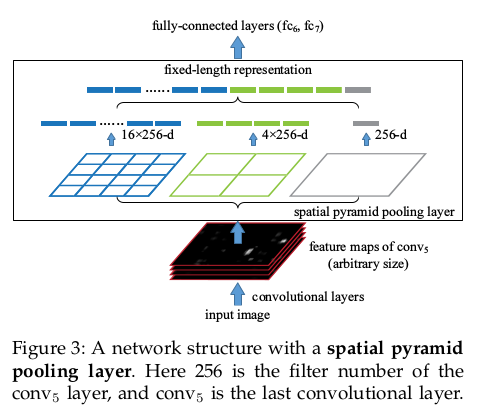
2.2 SPPnet
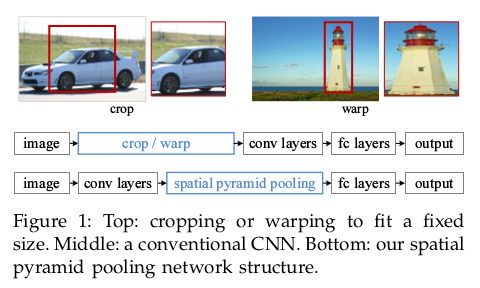
2.2.1. 共享计算
- 计算整张图片的卷积feature map, 这份map被用于后续的步骤
- 加入spatial pyramid pooling layer, 将多种size的feature map池化为固定大小的feature map, 这是为了适配后续的fc layers.
- SPPnet在检测阶段比RCNN快了10—100倍, 训练阶段比R-CNN快了3倍, 因为共享特征图
下图来自SPPnet论文
2.2.2. 缺点
- 与R-CNN一样, 训练都是多阶段进行的, 包含特征提取, 基于log loss微调网络, 训练SVMs, 最后训练bouning-box回归器
- features也要写入磁盘, 用于后续步骤
- 在微调阶段, 无法更新spatial pyramid pooling layer之前的卷积层, 这必然会影响检测精度.
3. Fast R-CNN
为解决R-CNN与SPPnet的缺点, 提出Fast R-CNN.
3.1. Fast R-CNN检测系统
- 检测步骤如下:
1) 图片通过selective search, 生成region proposals, 作为候选box 2)该图片再通过ConvNet, 生成一个feature map 3)feature map与region proposals一起进入ROI Pooling layer, 生成固定规格(7×7)的RoI features 4)RoI features通过两层fc layers, 生成固定大小的feature vectors, 这份vectors被复制为两份 5)分类: 一份进入关于分类的fc lyaer, 得到维度为K+1(e.g., 21)的向量cls_score, 再通过softmax layer得到维度为K+1的向量cls_prob 6) 位置: 一份进入关于位置的fc layer, 得到维度为(K+1)*4(e.g., 84)的向量bbox_pred 7) 优化: bbox_pred通过bbox regressors(K+1个)生成新的bbox_pred疑问: bbox regressors在哪个阶段进行训练的??? 这个问题, 现在看起来, 很显然, 只要得到了training RoI的真实targets与预测targets, 计算Loss, 再反向传播, 更新参数, 使得 targets 预测值不断趋近
- 优点如下:
1)比R-CNN、SPPnet的检测质量(mAP)都高
2) 除了selective search, 其他过程都可以一起训练
3) 采用了多任务loss
4)训练阶段可以更新所有网络层
5) 不需要保存特征, 用于训练, 这是训练一体化的结果
3.2. ROI pooling layer
RoI pooling layer将每个RoI的feature map转换为固定大小的RoI feature map, 伪码如下:
pooled_width = W
pooled_height = H
channels = C
spatial_ratio = 1/16 # 这是图片经过ConvNet缩小的比例
conv_feature_map = ConvNet(image)
RoIs = region_proposal(image)
for roi in RoIs:
# roi左上、右下顶点的像素坐标, 相对于原图
roi_x1, roi_y1 = [roi[0], roi[1]] * spatial_ratio # 左上顶点
roi_x2, roi_y2 = roi[2], roi[3] * spatial_ratio # 右下顶点
roi_width = roi_x2 - roi_x1
roi_height = roi_y2 - roi_y1
# roi的索引
roi_index = roi[4]
# pooled_map的每个像素点的对应的roi区域的宽高, 即构成了pool时的窗口
window_width = roi_width / pooled_width
window_height = roi_height / pooled_height
for i in range(pooled_height):
start_h = roi_y1 + i * window_height
end_h = roi_y1 + (i + 1) * window_height
for j in range(pooled_width):
start_w = roi_x1 + j * window_width
end_w = roi_x1 + (j + 1) * window_width
for c in range(channels):
pooling_conv_map = conv_feature_map[start_h:end_h, start_w:end_w, c]
pooled_map[roi_index, i,j, c] = max(pooling_conv_map)
3.3. Fast R-CNN的训练过程
3.3.1. 从预训练模型中初始化
在实验中, 使用了三个预训练模型, 它们具备5个max pooling layer、5-13个conv layer, 它们分别是
- CaffeNet:AlexNet版的R-CNN, 命名为model S
- VGG_CNN_M_1024:与model S一样深, 但更宽, 命名为model M
- VGG16: 这个模型是三个中最深的, 命名为model L
用上述三个预训练模型初始化前, 需要做出三个修改:
- 用RoI pooling layer取代最后的max pooling layer, 其中RoI pooling layer的输出的宽高是固定的, 这是为了适配后面的fc layer.
- 用两个slibing layers(fc layer + softmax (K+1 classes), class-specific bounding-box regressors(K+1 个))取代最后的fc layer与softmax layer(1000-classes)
- 网络的输入改为两个:图片list, 这些图片中的RoIs list
3.3.2. 关于检测的微调
可以利用back-propagation训练所有的参数, 这是Fast R-CNN一项重要的能力.
3.3.2.1 SPPnet无法更新spatial pyramid pooling layer之前层的参数的原因
- 由于每个训练样本(RoI)来自不同的图片, 经过spatial pyramid pooling layer的back-propagation是高度低效的.
- 上述低效是由“每个RoI都有感受野(receptive field), 这些感受野常常跨越整张图片”造成的: 由于forward pass必须处理整个感受野, 则训练时的输入是巨大的, 常常是整张图片
3.3.2.2 提出一种更高效的训练方法
-
本文利用训练阶段的特征共享, 提出一种更高效的训练方法:采用分层抽样, 假设每个mini-batch抽样 R 个RoI, 则先抽样 N 张图片, 再从每张图片中抽样 R/N 个RoI. 如此, 在forward与backward阶段, 来自相同图片的RoIs可以共享计算与内存.
-
减小 N, 可以减少mini-batch的计算量. 比如, 令 N = 2, R = 128, 上述方法比从128张图片中分别抽样1个RoI(这是SPPnet、R-CNN的抽样策略)快了大约64倍
除了分层抽样, Fast R-CNN把微调过程整合成一条流水线(一同训练, 不需要分段训练), 这个流水线联合训练softmax classifier、class-specific bounding-box regressors, 而不是像R-CNN那样在三个不同的阶段训练softmax分类器、SVMs、bounding-box回归器. 联合训练用到了multi-task loss.
3.3.3. 多任务loss
3.3.3.1. Fast R-CNN的两个输出
Fast R-CNN最后有两个输出, 对于一个training RoI:
- 第一个输出是(K+1)个类别的离散概率分布, 预测该training RoI属于各个类别的概率, 即
通常, $p$ 通过softmax计算最后一个fc layer的(K+1)维输出得到
- 第二个输出是
$K+1$个类别的bounding-box regression targets$t^k$, 即该training RoI 与 潜在 gt box 的bbox regression targets预测值, 有对于 class$k \in \{1,2,..,K\}$,
$t^k$刻画了属于class $k$ 的一个RoI propasal的尺度不变(x轴方向、y轴方向)转换值、对数下高/宽转换值, 具体可看R-CNN中的bounding-box回归.
注意, 这里预测了 K+1 个 bbox regress targets, 实际上计算Loss时只会用到一个类别的 targets 预测值, 具体看下面Loss
3.3.3.2. 定义multi-task loss
每一个training RoI, 都被一个ground-truth class $u \in \; K+1\;\text{classes}$(这个$u$怎么定义的? 见下面) 与一个ground-truth bounding-box regression target $v$ 所标记, 这样的training RoI被称之为labled RoI.
基于项目源码, 再复述一下上面的话, 对于一个training RoI,
- 找到该training RoI的对应gt box 通过计算它与所有gt box的IoU, 取最大IoU对应的gt box作为该RoI的对应gt box
- 确定标记该training RoI的类别
$u$: 其对应gt box所属类别, 即为该RoI的类别 - 计算该training RoI与其对应gt box的bbox regress target实际值
$v$
接下来, 对于上述training RoI, 模型会做出两个预测:
- 该 traing RoI 所属(K + 1)个类别的概率
$p = (p_0,\;p_1,\;...,\;p_K)$. - 该 traing RoI 的 (K + 1)个 bbox regress targets 预测值
$t^k = (t^k_x,\; t^k_y,\; t^k_w,\; t^k_h)$
注意, 虽然模型预测了 (K+1)个 bbox regress targets, 但计算 Loss 时只用到一个, 该 training RoI 所属类别的 targets, 即
$t^u = (t^u_x,\; t^u_y,\; t^u_w,\; t^u_h)$
为了联合训练分类器与bounding-box回归器, 下面为每一个labled RoI( 这个RoI被标记为ground-truth class $u$ 与 ground-truth bounding-box regression target $v$ )定义multi-task loss $L$:
其中:
- 分类 Loss 为
$[u \geq 1]$定义如下:
注意到, 被标记为 $u=0$ 的 training RoI 属于 background class, 没有对应的 ground-truth bounding-box, 它们在 $L_\text{loc}$ 中是被忽略的.
有了上述规定后, 对于bounding-box regression, 定义loss
其中,
需要指出的是, 当$|x|$很大时, 上述 $\text{smooth}_{L_1}(x)$是 $L_1$ loss, 比$L_2$ loss 更不敏感, 更具鲁棒性
3.3.4. mini-batch采样
在微调阶段, mini-batch采取以下抽样策略:
- ims_per_batch=2:在每个SGD的mini-batch中, 从训练图片集中均匀地随机抽取2张图片(在实际操作中, 在mini-batch训练前, 对整个训练图片集进行shuffle, 最后会得到一个索引list, 该list每个元素中含两张图片, 如此, mini-batch训练时依次从索引list提取一个元素作为mini-batch)
- mini_batch_size=128: 每个mini-batch会从该批次的图片中, 抽样提取128个RoI, 即从每张图片中提取64个RoI
- 25%:在mini-batch的128个RoI中, 有25%(32个)的RoIs是这样进行抽样的, 它们从 “与一个ground-truth bounding-box的
$\text{IoU} \in [0.5,\; 1]$” 的RoIs中抽样得到. 这些RoIs被标记为(foreground object)class$u \; \in \{1, 2, ..., K \}$
疑问:这样标记RoI, 不会造成“一个RoI会标记为多个class”吗, 因为一个RoI与多个属于不同类别的ground-truth bounding-box的IoU可能都大于0.5
回答上述疑问: 根据作者给出的源码, 每个 training RoI 事先会有一个”max_overlaps” 与 “max_classes”, 即该 training RoI 与 所有 gt boxes 的 IoU 的最大值, 其对应 gt box 的类别为 “max_classes”该值作为取样时的参考. 因此, 一个 sampling RoI 只会有一个标签.
按照上述理解, 个人认为论文写得不够严谨. “与一个ground-truth bounding-box的
$\text{IoU} \in [0.5,\; 1]$” 应该改为 “与所有ground-truth bounding-boxes的最大$\text{IoU} \in [0.5,\; 1]$”
- 75%:余下的75%(96个)RoI是这样抽样的, 它们从“与ground-truth bounding-box具有最大IoU属于 [0.1, 0.5) 的RoIs”中抽样得到, 这些RoI称之为”background examples”, 标记为
$u=0$($u$表示class index)
疑问:为什么要“最大IoU”?是不是要跟所有ground-truth bounding-box计算IoU进行比较?论文里没有说明白.
回答上述疑问: 根据作者给出的项目源码, 的确是最大, 是要跟所有ground-truth bounding-box计算IoU进行比较.
在实际操作中, 每个 training RoI 都带有两个属性:
roidb['max_classes'],roidb['max_overlaps'], 计算该 training RoI 与 所有 gt boxes 的 IoU, 经过最大值及其索引后, 即可得到这两个属性.
- 在训练时, 图片以0.5的概率被水平翻转, 除此之外, 未使用无其他数据增强方法
3.3.5. back-propagation through RoI pooling layer
RoI pooling layer的前向传播与后向传播, 在本质上与max-pooling layer(无重叠)是一样, 不同的是:
-
max-pooling: kernel_size、stride、pad是固定的, 而pooling后的map大小由输入map、kernel_size、stride、pad决定
-
RoI pooling: pooling后的map大小是固定的, 而kernel_size、stride由输入RoI决定
3.3.5. SGD超参数的设定
3.3.6. scale invariance
实现尺度不变的目标检测: 两种方式
-
“brute learning” learning: 在训练与测试阶段, 均采用固定的 scale (即固定的长边与短边) 进行 resize
-
image pyramids: 在训练阶段, 对已被加入 minibatch 的图片, 在 image pyramids 中为其随机选取一个 scale 进行按比例 resize
注: 项目源码里的 “按比例 resize” 是这样的, 最短边不大于固定 scale, 长边不超过 max_size, 并保持比例
3.4. 加速检测——采用truncated SVD
利用 SVD 分解, 维数为 u × v 的权重矩阵 $W$ 为
其中, $U$ 是维数为 u × u 的正交矩阵, $V$ 是维数为 v × v 的正交矩阵, $\sum$ 是维数为 u × v 的对角矩阵
-
对角矩阵 $\sum$ 对角线上的元素称为矩阵 $W$ 的奇异值
-
正交矩阵 $U$ 的列向量称为矩阵 $W$ 的左奇异向量
-
正交矩阵 $V$ 的列向量称为矩阵 $W$ 的右奇异向量
Truncated SVD, 是指截取部分奇异值作为近似, 假设取 $W$ 的前 t 个奇异值, 则
基于上述 Truncated SVD, 作者把权重矩阵为 $W$ 的 fc layer 拆分为两个 fc layer:
-
一个 fc layer 的权重矩阵为 $ \sum \nolimits {t×t} \, V{v×t}^T $, bias = 0;
-
另一 fc layer 的权重矩阵为 $U_{u×t}$,
bias为原来的bias
由此可见, Truncated SVD 将 fc layer 的参数量 从 $u × v$ 降至 $t(u+v)$. 当 $t$ 远小于 $min(u, v)$时, 参数量大幅减少.
4. 一些问题
4.1. 多任务loss训练是否有效果?
作者的实验证明, 多任务loss联合训练可以显著提高mAP.
4.2. scale invariance: to brute force or finese?
实验证明, 对于单尺度、多尺度训练得到的模型, 它们的检测表现几乎一样.
考虑到速度与精度, 采用单尺度训练模型.
4.3. 需要更多的训练数据吗
实验证明, 数据多多益善.
4.4. SVMs好于softmax吗
-
实验证明, softmax 的表现略胜于 SVMs.
-
虽然提升很小, 但是使用 softmax 可以进行一体化训练.
-
相比于
多个 “1对其它” SVMs, softmax 引入了类别内的竞争.
注: 在 R-CNN, 每个类别都有一个对应的 二分类 SVM (属于该 class, 不属于该 class), 即若有 $K$ 个 class, 则 有
$K + 1$个 SVM 分类器. (1是指background类别)
4.5. 更多proposals就一定有助于提高精度吗
太多反而会有害
注: fc layer: fully-connected layer
参考文献
[1]. Ross Girshick, Fast R-CNN.
[2]. Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.
[3]. Jonathan Hui, What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
