论文题目:Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
论文作者: Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik UC Berkeley
1. 摘要
1.1. 研究背景简述
-
目标检测的性能已经很多年来未得到显著的提升(基于PASCAL VOC数据集)
-
过去最好的目标检测算法——complex ensemble systems that typically combine multiple low-level image features with high-level context
1.2. 本文的工作
- 提出一种simple and scalable detection algorithm——其在PASCAL VOC2012上的mAP为53.3%(超出在这个数据集上已有的最好算法30%多)
1.3. 本文的两个关键点
-
CNNs: 为定位与分割目标,将深度卷积神经网络应用于每一个region prosopal
-
预训练与微调: 当标记数据缺乏时,首先在一个辅助数据集上进行监督型预训练(这个任务称为辅助任务),之后在一个特定数据集上进行fine-tuning,这使检测性能得到了很大的提升
1.4. R-CNN的由来
combine region proposals with CNNs, R-CNN: Regions with CNN features.
2. 研究背景
2.1. 过去十年进步缓慢
- SITF与HOG的使用在多个视觉识别任务中,过去十年所取得的进步大部分都基于SIFT与HOG的使用. 需要注意的是,在PASCAL V0C2010-2012的目标检测方面,进步很小,而这些小进步来源于“建立集成系统与对成功方法的小改动”
SIFT and HOG are blockwise orientation histograms, a representation we could associate roughly with complex cells in V1, the first cortical area in the primate visual pathway. But we also know that recognition occurs several stages downstream, which suggests that there might be hierarchical, multi-stage processes for computing features that are even more informative for visual recognition.
- SIFT与HOG: SIFT与HOG可大致反映灵长类动物视觉回路的V1区域的活动
2.2. 视觉识别发生: 多层、多阶段
-
研究表明,视觉识别发生在V1下游的多个阶段
-
也许存在多层、多阶段的过程,用于计算在视觉识别中更具表征作用的特征
2.3. Fukushima’s “neocognitron”(1980)
-
neocognitron是模拟多层、多阶段视觉识别的早期尝试
-
neocognitron是一个用于模式识别的模型,它是受生物学启发,具有多层、平移不变性的性质
-
neocognitron的缺点: 不具备监督训练算法
2.4. LeCun的工作(1989)
- 基于Rumelhart的工作(1986), 证明了“通过后向传播,SGD能有效地训练CNN”,CNN被认为是neocognitron的拓展
2.5. CNN的发展简史
-
辉煌-1990年代被大量研究与运用 –> 没落-1990年代后,SVM的兴起 –> 重回辉煌-Krizhevsky、Hinton等人设计的CNN在ILSVRC2012图像分类任务上夺得冠军(以绝对优势)
-
他们在120万的图片上训练CNN
-
在LeCun的CNN上作了些改动(加入ReLU与dropout正则化)
2.6. ILSVRC 2012研讨会的热点问题
CNN在ImageNet分类任务上的性能可以在多大程度上泛化到PASCAL VOC的目标检测任务上?由此引出本文的研究点: 缩小图像分类与目标检测的差别来回答上述问题
2.7. 本文的工作
首次提出“CNN在PASCAL VOC目标检测任务上表现优异”,为实现该结果,主要解决两个问题:
-
用深度网络定位目标
-
在小规模的标记数据集上训练深度模型
2.8. 定位目标的方法
2.8.1. 法一: 将定位问题转换为回归问题
2.8.2. 法二: 建立滑动窗检测器
- 滑动窗检测器是指在图像上从左到右、从上到下滑动窗口,利用分类来检测目标,如下图所示

-
为检测在不同视觉距离(viewing distances)下不同种类的目标,将使用不同大小与宽高比的滑动窗
-
从滑动窗中提取到patches, 由于很多分类器要求固定大小的图片, patches均被warped成固定大小, 注意: 由于分类器将会被训练成处理warped image patch, 则这个warped不会影响分类精度。

- 检测步骤如下:
a) 滑动窗口; b) 基于滑动窗,提取patches; c) warped: patches均被warped成固定大小; d) 提取特征: warped image patch被丢进CNN分类器提取一个4096维的特征; e) 分类与box微调: 应用SVMs分类器来分类,应用线性回归器来微调box - 滑动检测器的系统流如下:
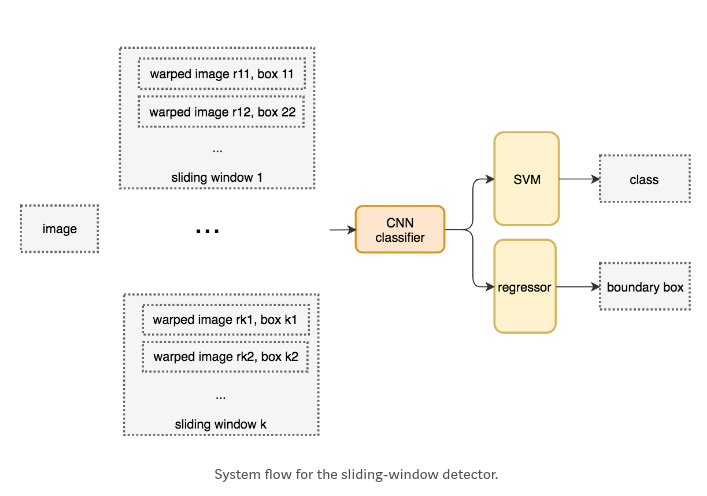
- 下面是检测伪代码. 为检测在不同位置上不同的目标,建立了很多窗口. 为提高精度,一个明显的方案是减少窗口的数量.
for window in windows patch = get_patch(image, window) results = detector(patch) -
为保持高的区域分辨率,这些CNNs通常只有两个conv-pooling层(作者这么说的)
- 本文也尝试过采取滑动窗方式,但是
units high up in our network, which has five convolutional layers, have very large receptive fields (195 × 195 pixels) and strides (32×32 pixels) in the input image, which makes precise localization within the sliding-window paradigm an open technical challenge.
2.8.3. 基于region进行识别
本文利用区域进行识别(“recognition using regions” paradigm),这种方法已被成功应用于目标检测与语义分割
2.9. 标记数据少时训练模型的方法
标记数据集太少,不足以训练深度CNN,解决方法有:
-
法一: 无监督型预训练 –> 监督型微调
-
法二: 在大型辅助数据集上进行监督型预训练(辅助任务) –> 在小数据集上进行domain-specific微调
本文采用的是法二,实验证明,在标记数据(目标数据)缺乏时,法二是训练深度CNN的有效途径,微调可以提高mAP8个百分点
2.10. R-CNN与OverFeat的对比
-
OverFeat利用滑动窗CNN进行检测,是200类ILSVRC2013目标检测数据集目前为止表现最好的算法
-
基于上述数据集,R-CNN完胜OverFeat
3. R-CNN目标检测系统
R-CNN目标检测系统由三个模块组成:
- 模块1: region proposals生成模块——selective search method,负责生成类别独立的region proposals,这些proposals将作为候选nox送给检测器
- 模块2: 特征提取模块——CNNs,负责从每一个region proposal提取一个4096维的特征
- 模块3: 分类与box微调模块——SVMs与Bounding-box regressors,注意: SVM与Bbox regressor都与类别相关,即一个类别对应一个SVM、一个Bbox regressor
- 模块4:非极大抑制,过滤掉得分较低且与得分较高的region的重叠超过阈值的region proposal
该目标检测系统的示意图如下,下图1来自R-CNN论文,图2来自Girshick et al. CVPR14
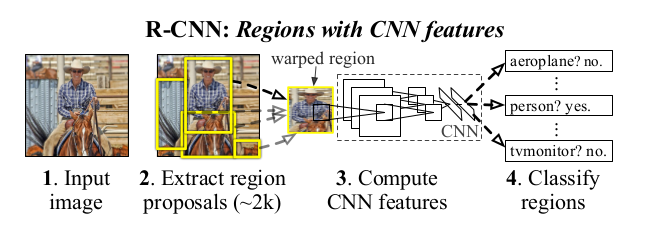
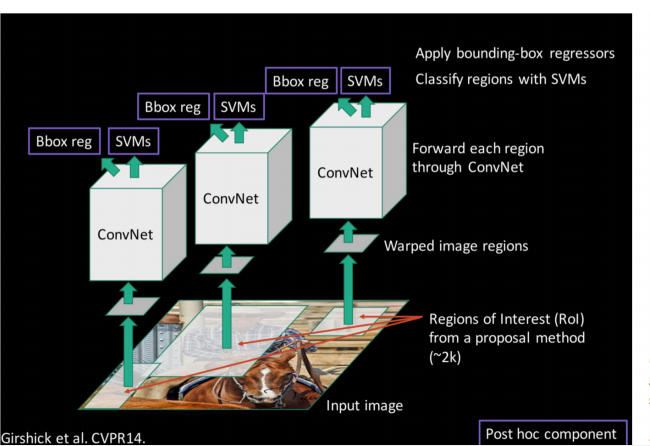
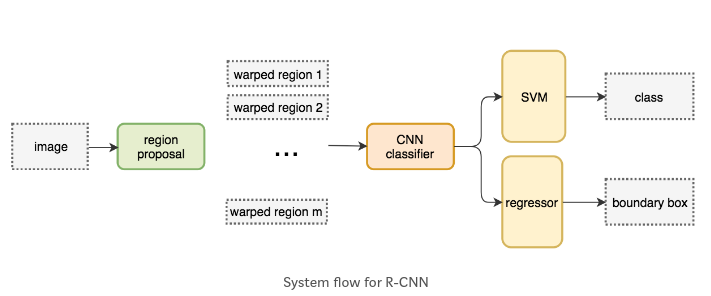
由于生成少而高质量的RoIs,因此R-CNN比滑动窗检测速度更快、mAP也更高. 下面是检测伪码:
ROIs = region_proposal(image)
for ROI in ROIs
feature = get_feature(image, ROI)
results = detector(feature)
3.1. 模块1:region proposals生成模块
- 采用selective search来生成类别独立的region proposals,步骤如下:
a) 把每一个像素点当成一个区域 b) 计算每一区域的texture,把texture相近的区域合并为一个区域,为防止小区域吞并其他区域,先合并小区域 c) 继续计算并合并区域,直到无法合并区域下图的第一行展示了如何生成regions,第二行中的蓝色矩形框展示了在合并过程中所有可能的ROIs(Regions of Interest)

- 输入:一张图片
- 输出:~2000个region proposals
3.2. 模块2:warped模块
- 将每一个region prosopals都warp成227*227 pixels
- 在原来的region proposal周围将补上16个像素点的图片背景,这些添加的图片背景来自原图,下图展示了几种训练CNN前处理region proposals的方法,它们来自R-CNN论文.

3.3. 模块3:特征提取模块
- 采用CNN来提取特征,每一个proposal都将通过CNN产生特征
- CNN的结构:5个卷积层,2个全连接层
- 输入:一个被warp成227*227的proposal
- 输出:一个4096维的特征向量
3.4. 模块4:检测与box微调模块
region proposal的4096维特征向量将会被复制两份,分别传入SVMs分类器与Bounding-box回归器
3.4.1. 检测
-采用SVMs分类,每一个类别都会有一个SVM分类器,每一个类别的SVM分类器会给出这个proposal属于该类别的概率,即SVMs分类器作为检测器
- 输入:4096维的特征向量
- 输出:含N+1个概率的向量(假设有N类目标,1是指background)
3.4.2. 基于proposal预测新的box
- 采用Bounding-box回归器,对region proposal进行微调,来减少定位误差
- 输入:proposal的(Px, Py, Pw, Ph),表示中心的像素点坐标、宽与高(基于pool5 features)
- 输出:新的proposal的四维坐标表示

4. R-CNN模型训练
4.1. 监督型预训练CNN:
基于ImageNet 2012分类数据集,进行分类任务的训练
- 优化方法:SGD
- 学习率:0.0001
4.2. Domain-specific微调
4.2.1. 修改分类层
为使得上述预训练得到的CNN模型适配新任务(检测)与新领域(warped region proposals),继续基于上述CNN模型在PSACAL VOC检测数据集进行fine-tuning,为此只需要作出下列修改
用随机初始化的(N+1)维分类层替换上述CNN中1000维分类层,其中N是指目标物的类别数,1是指background
4.2.2. 正、负样本的定义
- 正样本:与某个ground-truth box的IoU >= 0.5的region proposal
- 负样本:不属于正样本的region proposal
4.2.3. 超参数的设定
- 优化方法:SGD
- 学习率:0.001
- mini-batch size: 128
- mini-batch抽样规则:抽样32个正样本(来自所有目标类), 96个background windows (这是啥意思,没有定义,是指负样本吗??)
4.3. (N+1)个SVM分类器的训练
注意:这里将会为每一个目标类别训练一个SVM分类器. 因此,下面将针对训练关于car的SVM分类器进行陈述,其他类别类似进行训练.
4.3.1. 关于car的正、负样本的定义
- 正样本:属于car的ground-truth box
- 负样本:与所有属于car的ground-truth boxes的IoU都低于0.3的region proposal
4.3.2. 讨论:为何使用不同的正、负样本定义——fine-tuning与SVMs训练
-
SVMs的正负样本定义起源:开始是用ImageNet pre-trained CNN提取的特征来训练SVMs, 此时采用上述SVM阶段正、负样本定义(因为在一系列的正负样本定义之后(包括上述fine-tuning阶段正负样本定义),这是最优的定义)
-
微调CNN采用SVMs的正负样本定义,效果比其现有定义更差
作者认为,SVMs与fine-tuning阶段正负样本定义的不同,是源自有限的fine-tuning数据.
fine-tuning采用的正负样本定义将会产生很多“jittered”样本,这些proposals与ground-truth box的IoU处于[0.5, 1],但它们都不是ground-truth box.
这种定义可以将fine-tuning阶段的正样本的数量扩大大约30倍,这些庞大的正样本数量将有助于在fine-tuning CNN时防止过拟合.
注意: 使用这些“jittered”样本作为正样本,将会导致无法充分地微调网络,使之用于精确地定位
4.3.3. 讨论: 在fine-tuning后,为何训练SVMs来检测?
- 直接在fine-tuning网络后加一个21类softmax回归器作为检测器,不是更直接吗?
作者尝试过使用21类softmax分类器作为检测器,但是这种策略将会使mAP从54.2%降到50.9%(基于VOC 2007)
上述mAP的下降可能来源于很多因素,包括fine-tuning阶段的正样本定义无法强调精确的定位,softmax分类器的负样本是randomly sampled(这是啥意思?不都是随机抽样吗?),而SVMs是在“hard negatives”的子集中进行训练
4.4. Bounding-box regression(class-specific)
为SVM后的scored proposal预测一个新的bounding-box,注意:这里的bounding-box regressor与目标类别相关,有多少个目标类别就有多少个这样的regressor.
4.4.1. 这里的回归与DPM中Bounding-box回归的不同
- 这里的bounding-box regression类似于DPM中的bounding-box回归,不同的是这里回归的变换函数是基于由CNN计算的特征(pool5特征),而DPM中的bounding-box回归的变换函数是基于是DPM位置预测部分给出的几何特征.
为何不是fc7 feature,因为需要位置信息,fc7 feature是一个向量,无法表示位置信息
4.4.2. 训练回归器的准备
- 数据集,如下图所示.

- 回归目标:学习一个转换,这个转换可以将一个已经提出的box P 映射到一个ground-truth box G,这个转换的定义如下图所示. 如此,我们的回归目标就是学习上述四个转换函数

4.4.3. 四个转换函数的定义及学习
- 四个转换函数被定义为proposal pool5 features的线性函数,那么,我们的学习目标就是学习这些函数的参数,如下图所示.

4.4.4. 实现bounding-box regression需要注意的问题
-
正则项参数的设定:lambda = 1000 based on a validation set
-
选择训练对(P, G):挑选至少“靠近”一个ground-truth box G 的proposal. “靠近”是指与某个ground-truth box G 的IoU最大,且这个IoU大于阈值0.6(在验证集上设为0.6). 其余proposal将不会放入训练.
-
在测试阶段,为每一个scored proposal预测新的box,当且预测一次,因为实验证明多次预测并不能提高定位精度.
5. 其他
5.1. 一些结论
-
低层filters捕获oriented edges与oppoent colors.
-
本文的主要误差是定位误差,bounding-box regression可以在很大程度上减少定位误差
-
本文还提到了如何划分ILSVRC2013检测数据集,分割ILSVRC2013数据集与PASCAL VOC上的分割有所不同,因为ILSVRC的样本更不同质,不均匀.
5.2. ILSVRC2013检测数据集
5.1.1. ILSVRC2013检测数据集构成
train(395,918), val(20,121), test(40,152), 其中括号里的数字表示各个数据集的图片数
5.1.2. val set与test set: 相同的图片分布,全部被标记
-
它们在场景、复杂度(目标数、杂乱程度、动作多样性)上都相似
-
图片里属于200类目标的物体全部用bounding-box标记
5.1.3. train set: 复杂度更高、仅部分被标记、包含负样本
-
来源于ILSVRC2013分类数据集,因而图片复杂度更高
-
由于图片数巨大,仅部分图片被用bounding-box标记
-
每一个类别都有负样本,这些负样本被人工确认不含200类中的目标,负样本在本文中不参与训练
5.2. 构建训练样本
5.2.1. 问题:
-
由于train set未被全部标记,则train set无法用于hard negative mining –> 问题:负样本从哪来?
-
由于train set与val/test set的图片分布不一致 –> 问题:train set可以用于训练吗?如果可以,用多少比例?
5.2.2. 解决方案
-
主要依靠val set,将train set的部分图片作为辅助正样本的来源
-
将val几乎均等地分为val1、val2:由于部分类别的图片数量少,最少的只有31张,图片数少于110的类别占一半,因此需要生产近似类别均匀的划分(每个类别的样本都均匀分布)
a) 首先对val images进行聚类(K为目标类别数); b) 采取随机局部搜索:样本数多的类别用方法产生,样本少的类别直接选入
说明:关于在ILSVRC2013检测数据集上训练R-CNN的其他细节这里不再叙述,如有时间再写.
图片来源说明: 本文的图片若不特别指明,均来自文章“What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?”
参考文献
[1]. Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik, UC Berkeley, Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
[2]. Jonathan Hui, What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?
